AI Software Engineering: current shifts and constraints
Cognitive throughput is becoming the new platform constraint.

Context
We are currently navigating a fundamental platform shift that reshapes technology every 10 to 15 years, moving from the eras of PCs, the Web, and Smartphones into the reality of Generative AI. As we look toward the second half of 2026, we are not merely witnessing an evolution in toolsets but a radical transformation of our developer ecosystems and the very nature of professional work.
Working thesis: shifts being combined
I want to share a working thesis about where the AI developer ecosystem is heading. Please note that many pieces of this puzzle are being moved and tested simultaneously, but it reflects my frontline reading and experience.
The short thesis version is this: AI will not just make software faster to write. It will turn software development into a much higher-throughput system, and once that happens, the scarce resource changes. The constraint is no longer only developer time or model access. It becomes cognitive throughput: how much useful, validated, economically sensible work can an organization safely absorb?
I am watching four shifts. First, hardware and software can no longer be optimized in isolation (e.g., #1, #2, #3). Second, agentic workflows (e.g., #4, #5) have to become economically viable, not just impressive in demos (we are past Karpathy's vibe coding era). Third, orchestration has to move from reactive scheduling to predictive control. And fourth, the industry has to move beyond performance and TCO (Total Cost of Ownership) as the only metrics, because cheaper cognition will create more demand for cognition.
The frame here is deliberately exploratory: if these shifts are real, what kind of developer ecosystem, and what kind of company, should exist next?
Macro shifts
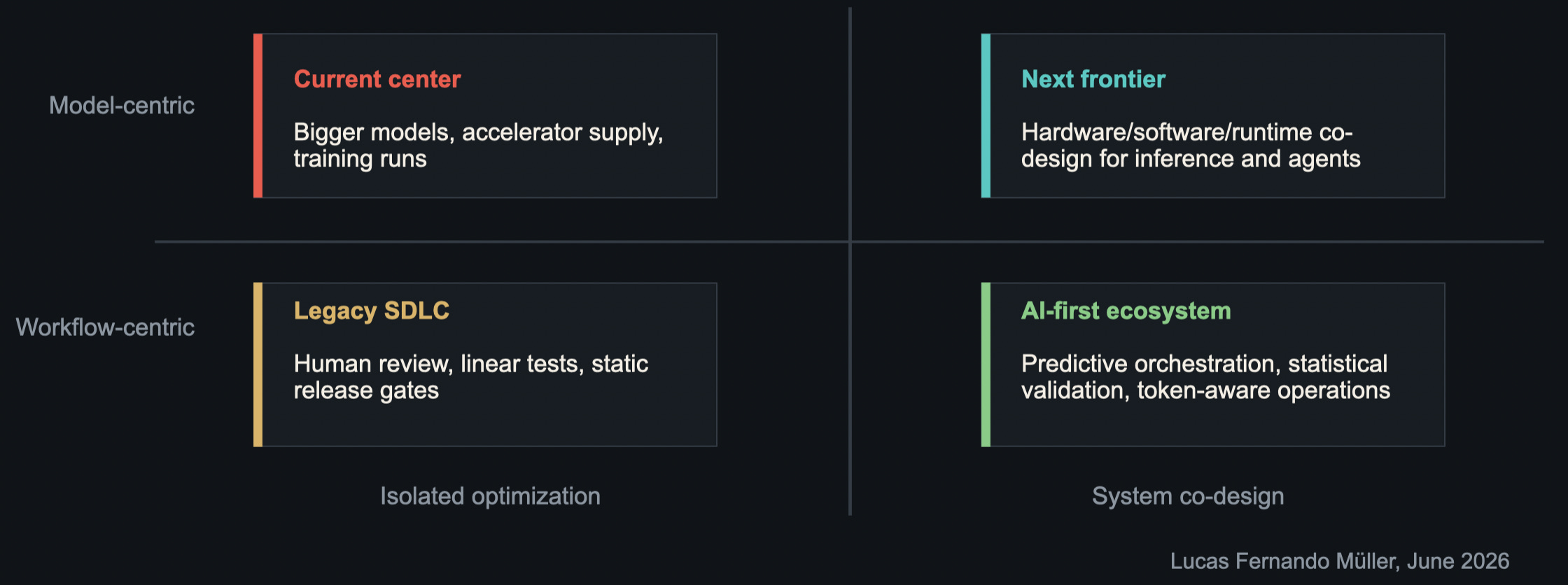
For the last few years, the center of gravity has been model-centric: larger models, GPUs/accelerators (specialized AI hardware) availability, training runs, benchmark performance. Those things still matter. But it is clear to me that the next frontier is less about any single component and more about how the full system behaves.
In the diagram above, I portray this moment. On the top-right, the shift is toward hardware-software-runtime co-design. Inference and agentic execution are revealing bottlenecks that do not appear when we think only in terms of model quality or raw FLOPs. In the bottom-right corner, the same thing is happening inside the software development lifecycle. The legacy SDLC assumes a relatively human-paced process: write code, review code, run tests, ship, roll back if needed. But AI-first development changes the volume and velocity of activity. The system has to become schedulable, observable, and governable.
My claim here is that the opportunity is probably not “yet another coding assistant”. The opportunity sits one layer deeper: the control plane that helps organizations understand and manage this new AI-driven engineering throughput.
Agentic scale
Let me make the infrastructure point more concrete. A lot of public conversation still collapses AI infrastructure into GPUs. GPUs are critical, of course, but agentic workflows are not just continuous model inference. An agentic coding session has multiple phases.
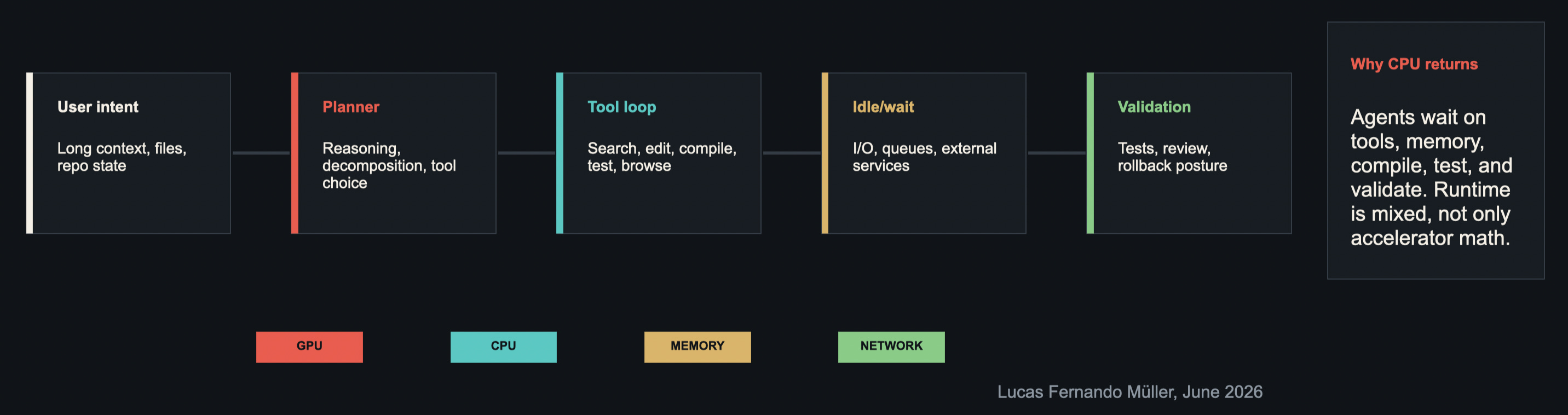
A user provides intent, files, and repo context. A planner decomposes the work.
Then the system enters a tool loop: search, edit, compile, test, browse, wait on external services, retry, and validate. In that loop, the workload is mixed. There are bursts of reasoning, but there is also memory pressure, I/O, waiting, compilation, network activity, and coordination overhead. That is why I anticipate CPU demand and broader system efficiency returning to the conversation. Multi-turn agents can spend a meaningful part of their runtime not doing accelerator math, but coordinating work around it.
My message is simple: if agents become a normal interface to software work, the economics are about utilization and end-to-end throughput, not just model quality.
Orchestration
In many systems today, orchestration is reactive. Work arrives, queues form, jobs are routed, and the system responds. That is enough when workloads are relatively predictable or when the cost of a bad schedule is low.
Agentic workflows are different. They are long-running, multi-step, and uncertain. One task might be a small edit. Another might fan out across files, trigger tests, consume a lot of context, and sit idle while tools run. If every agentic job is treated the same, costs and latency become unpredictable very quickly.
So orchestration has to mature, and I foresee a race in this space alone. First, it becomes policy-aware: budgets, model tiers, priorities, and service levels matter. Then it becomes predictive: before a task runs, the system estimates memory, tool waits, retries, and validation needs. Eventually, it becomes learning-based: schedules improve based on observed outcomes.
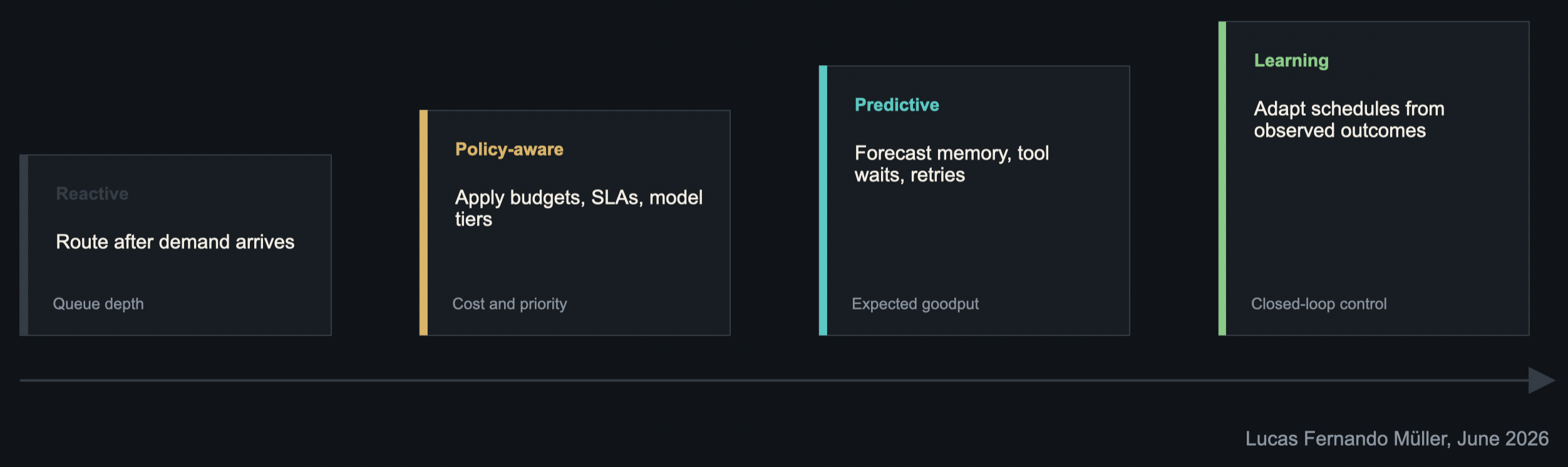
The question is: what would it mean for a developer ecosystem scheduler to become the SRE (Software Reliability Engineering) brain for agentic work? Can a system intelligently manage AI agents the way SREs manage production systems? In practice: predict workload, route tasks, control cost, prevent failures, enforce reliability, and learn from outcomes.
Usage economics

Table 1 is one of the clearest public signals that the market is already moving in this direction. Across the major AI products, usage limits are becoming less like simple message counters and more like dynamic compute budgets.
Google, Anthropic, OpenAI, and Microsoft each describe limits differently, but the pattern is similar. Complexity matters. Files matter. Context length matters. Model choice matters. Long-running coding work matters. The unit being governed is not just a prompt; it is work performed by a system.
This matters because pricing and policy often reveal the shape of the underlying cost structure before the product language catches up. Users may still think in terms of chats, but vendors are increasingly managing capacity in terms of tokens, context, execution time, model multipliers, and task complexity.
I will not over-index on the exact policy details because they will keep changing.
The durable point is this: AI work is becoming metered infrastructure, which creates a need for visibility, forecasting, and prioritization (e.g., #6).
Connecting the dots: the agentic reality
The connection between infrastructure and engineering lies in the realization that “intelligence is becoming a utility”, much like electricity or water. So, let’s connect the usage-economics point to software development.
The optimistic story is that AI gives us 10x more software activity (i.e., Silicon Valley's 10x engineers saying, e.g., #7, #8). The uncomfortable follow-up is: what happens to the ecosystem when that activity actually arrives (and we are indeed already seeing the impact)?

Code is not just an asset. It is also a liability. Every line has to be understood, maintained, secured, tested, integrated, and eventually changed or removed. If we generate code 10x faster, we may also generate organizational liability 10x faster.
Infrastructure is starting to feel the pressure, too. Compile times grow (yep, not everything is web technologies). Binary sizes grow. Microservice chatter grows. Version control systems that were optimized for consistency feel too slow for AI-speed workflows (see the plethora of challengers, e.g., #9, #10, #11, etc). And release management becomes harder because many changes can land before the organization fully understands the consequences.
The point is not that AI coding is bad. The point is that a productivity increase becomes a systems problem. If we only celebrate the code-generation speed, we miss the bottlenecks that decide whether that speed becomes value or entropy.
Validation
Validation is probably the first hard ceiling (see #12, #13, #14, #15). Traditional quality systems assume that tests scale in a manageable way and that the organization can still require a mostly deterministic all-green gate before shipping.
But dependency graphs do not always grow linearly. As systems get larger, the number of interactions can grow much faster than the amount of code. In a world with 10x more code and 10x more activity, the test and validation burden can become 100x or even 1,000x as expensive in practice.
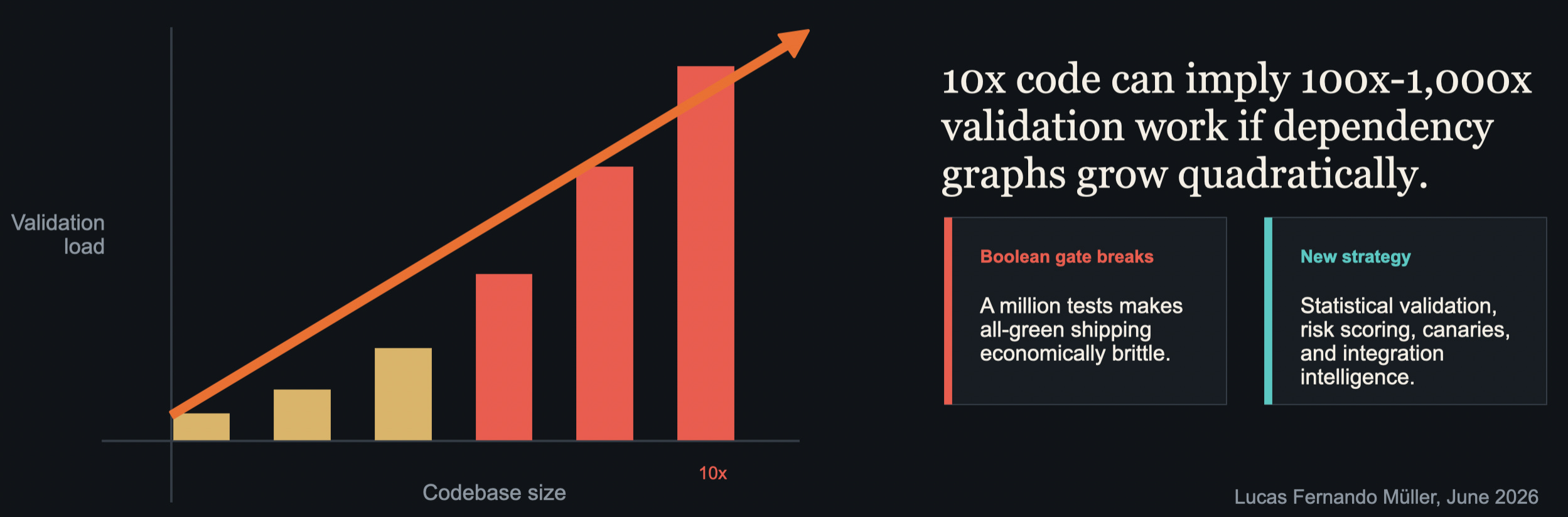
That raises a hard question: what happens when you have a million tests and cannot realistically require every single Boolean to be green before anything ships? Maybe the future quality system has to be more statistical, more risk-scored, more staged, and more integrated with production signals.
I would emphasize that this is not an argument against tests. It is an argument for a new validation architecture, because agentic development may overwhelm the old one.
Human oversight
The uncomfortable possibility is that humans become the bottleneck not because they are slow typists, but because judgment is scarce. Today, humans often encounter codebase changes through code review. But if AI systems produce far more edits, reviews become fragmented. People may see individual diffs without understanding the system’s trajectory.
There is also a leadership problem. A junior developer with many agents can suddenly produce the activity level of a much larger team. Still, they may not have the architectural intuition that normally comes from years of operating inside complex systems.
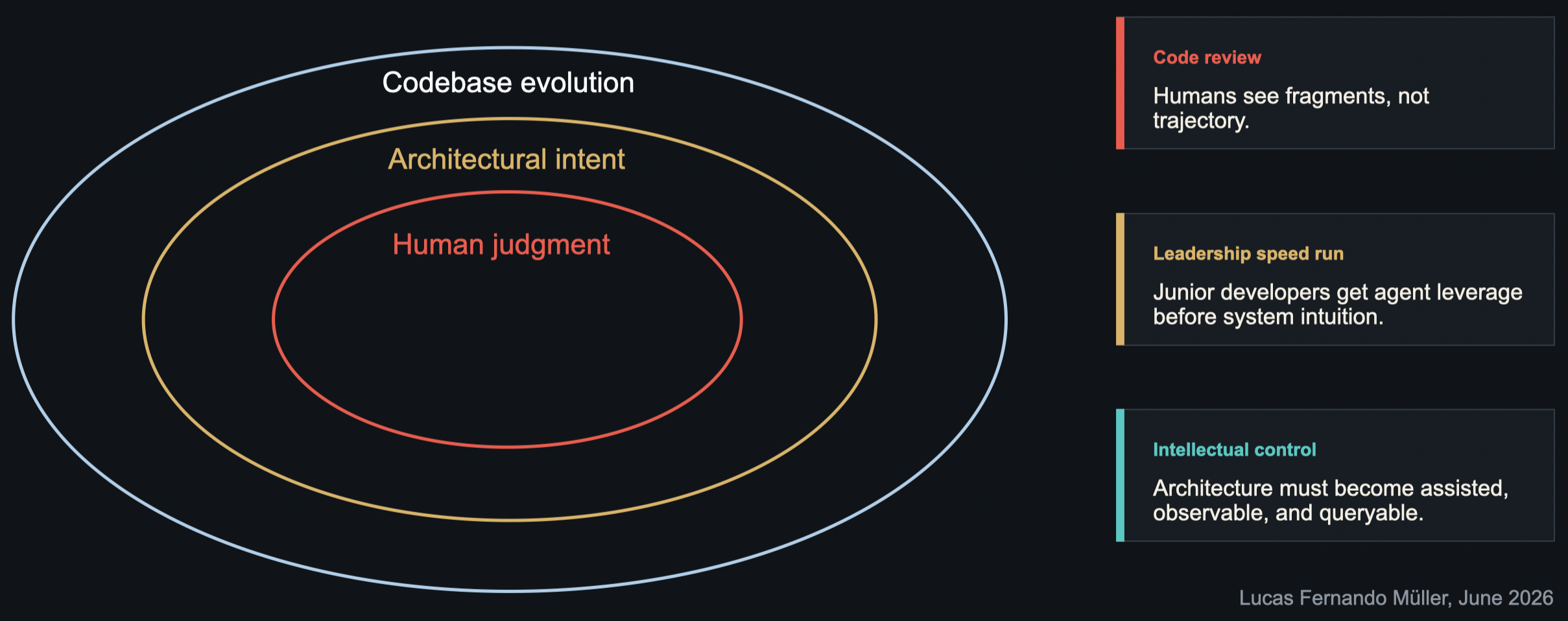
The core point here is intellectual control. Can humans still reason about the systems they are building? If not, the answer cannot simply be fewer agents. It probably has to be AI-assisted architecture, observability, review, and governance. The human role shifts from writing every change to maintaining intent, constraints, and judgment over the system.
Metrics
A lot of infrastructure buying conversations default to performance and total cost of ownership. Those still matter, but I do not think they are sufficient for an AI-first developer ecosystem, where not just model performance, but how efficiently the whole engineering system turns AI-driven work into useful, reliable shipped software.
Jevons Paradox is a useful warning. When a fundamental resource becomes dramatically more efficient, total consumption of that resource often rises. If cognition becomes cheaper, we should expect greater demand for it, not less. So the question becomes: what kind of cognition are we producing? Is it useful? Is it validated? Is it energy-efficient? Does it increase or reduce system risk?
That is why metrics like goodput, intelligence per watt, carbon efficiency, and rollback posture become important. Goodput asks how much useful completed work the system produces, not just how much activity happened. Rollback posture asks whether the organization can recover safely under higher change velocity.

The takeaway is that cheaper tokens are not the end goal. Valuable, reliable, energy-aware cognition is the goal.
Culture
Culture is important (critical, I must say) because AI does not enter a vacuum.
It amplifies the system it enters. If an organization has weak fundamentals, AI can accelerate hidden debt. Everyone can create custom tools, but nobody owns the maintenance. Agents can produce edits quickly, but the release process may not be able to absorb them. Internal APIs that were never hardened may suddenly be discoverable and callable by automated systems.

In a stronger organization, the same AI capability looks very different. Documented practices, clear ownership, good release hygiene, and explicit social contracts turn agentic workflows into leverage rather than chaos. This is why I think any serious AI-first developer ecosystem has to map both the technical and the social graphs. The diagnostic question is not just “what tools do you use?”, it is: what does this organization actually value when speed, quality, cost, and ownership collide?
Where do we go from here on?
If you are still reading, I’m assuming you have this same question in mind. If my initial thesis is correct, we need a developer ecosystem control plane built for AI-first engineering activity. I would describe the product surface in four verbs.
Map: understand the technical and social graph of the developer ecosystem.
Forecast: identify what breaks when activity grows 10x.
Govern: manage tokens, internal APIs, budgets, release posture, and agent permissions.
Validate: create risk-scored quality gates that match the new velocity.
The important thing is that this is not just about observability or just about developer productivity. It is the layer that connects activity, cost, quality, architecture, and organizational control. The premise: make AI-driven engineering activity observable, schedulable, governable, and culturally survivable. Worth noting that hyperscalers (AWS, Google, Microsoft) don’t yet have a cohesive solution for all of the points discussed here; each has different critical parts, but they remain disjoint tools, which allows neoclouds to build and explore solutions (e.g., #16, #17, #18, #19).
All in all, the discussion here provides valuable insights into the industry’s trajectory and highlights where its focus should go for the 2nd half of 2026.